摘要
本书 《Python Concurrency with asyncio》 , 是 manning 上的一本关于 Python asyncio 的书籍,在这之前对 Python 的协程接触不多,读完后了解了大概,知道了一些使用套路和常用的 API,是一本不错的 Python asyncio 的数据。
第一章 并行和并发 并发,我们可以同时进行多个任务,但在给定时间点只有一个是我们正在积极进行的。而并行则表示多个任务同时进行且我们正在同时积极地处理多个任务。
GIL 锁 GIL防止一个Python进程在任何给定时间执行多于一个的Python字节码指令,也就是说,即使我们在具有多个核心的机器上拥有多个线程,Python进程也只能一次运行一个线程的Python代码。
即,GIL锁是每个进程一个,当在一个进程中有多个线程时,由于GIL的存在,这些线程并不能并发运行。 由于每个 Python 进程都有自己的 GIL,所以多进程可以并发地运行多个字节码指令。
全局解释器锁在发生 I/O 操作时被释放。这允许我们使用线程在处理 I/O 时进行并发工作,但不适用于 CPU 密集型的 Python 代码本身,所以多线程适合IO密集的场景。
这是因为在I/O的情况下,低级别的系统调用在Python运行时之外。这使得GIL可以被释放因为它没有直接与Python对象交互。在这种情况下,只有当接收到的数据被转换成Python对象时,GIL才会被重新获得。然后,在操作系统级别上,I/O操作会同时执行。
asyncio 并没有规避 GIL,我们仍旧受到其限制。如果我们有一个 CPU密集的任务,仍然需要使用多个进程并发执行,这样才能高效率。
多进程代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 import multiprocessingimport os def hello_from_process () : print(f'Hello from child process {os.getpid()} !' ) if __name__ == '__main__' : hello_process = multiprocessing.Process(target=hello_from_process) hello_process.start() print(f'Hello from parent process {os.getpid()} ' ) hello_process.join()
多线程代码示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import timeimport threadingimport requests def read_example () -> None : response = requests.get('https://www.example.com' ) print(response.status_code) thread_1 = threading.Thread(target=read_example) thread_2 = threading.Thread(target=read_example) thread_start = time.time() thread_1.start() thread_2.start() print('All threads running!' ) thread_1.join() thread_2.join() thread_end = time.time() print(f'Running with threads took {thread_end - thread_start:.4 f} seconds.' )
操作系统事件通知 asyncio 被抽象化了,它会根据我们的操作系统支持的通知系统的不同而切换。以下是特定操作系统使用的事件通知系统:
kqueue - FreeBSD和MacOS
epoll—Linuxepoll - Linux
IOCP - Windows
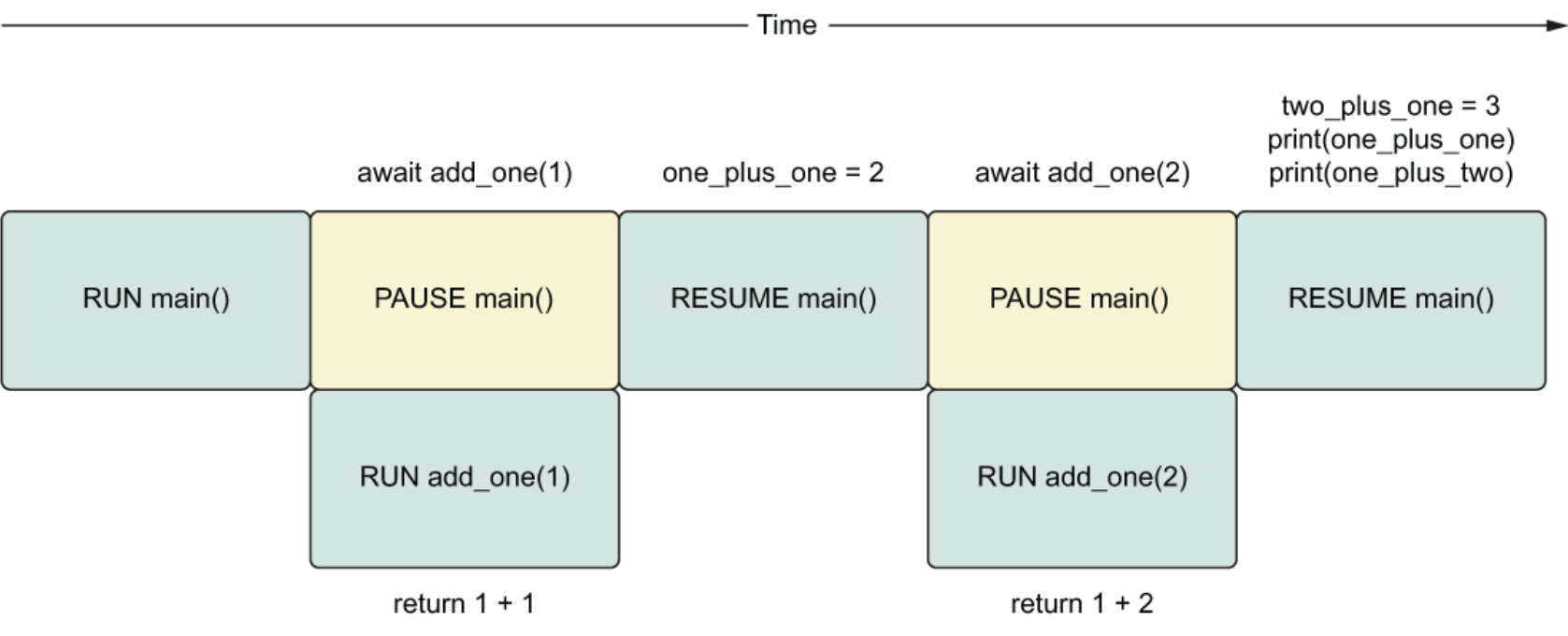
第二章 简单协程示例 1 2 3 4 5 6 7 8 import asyncio async def coroutine_add_one (number: int) -> int: return number + 1 result = asyncio.run(coroutine_add_one(1 )) print(coroutine_add_one(1 )) print(result)
添加 await 关键字 使用 await 关键字会使其后面的协程运行,不同于直接调用协程会生成一个协程对象。await 表达式还会暂停包含它的协程(父协程),直到我们等待的协程完成并返回结果。当等待的协程完成后,我们将可以访问返回的结果,并且包含它的协程(父协程)将会“唤醒”以处理结果。
1 2 3 4 5 6 7 8 9 10 11 12 import asyncioasync def add_one (number: int) -> int: return number + 1 async def main () -> None : one_plus_one = await add_one(1 ) two_plus_one = await add_one(2 ) print(one_plus_one) print(two_plus_one) asyncio.run(main())
目前而言,这段代码与普通的顺序代码执行没有区别。
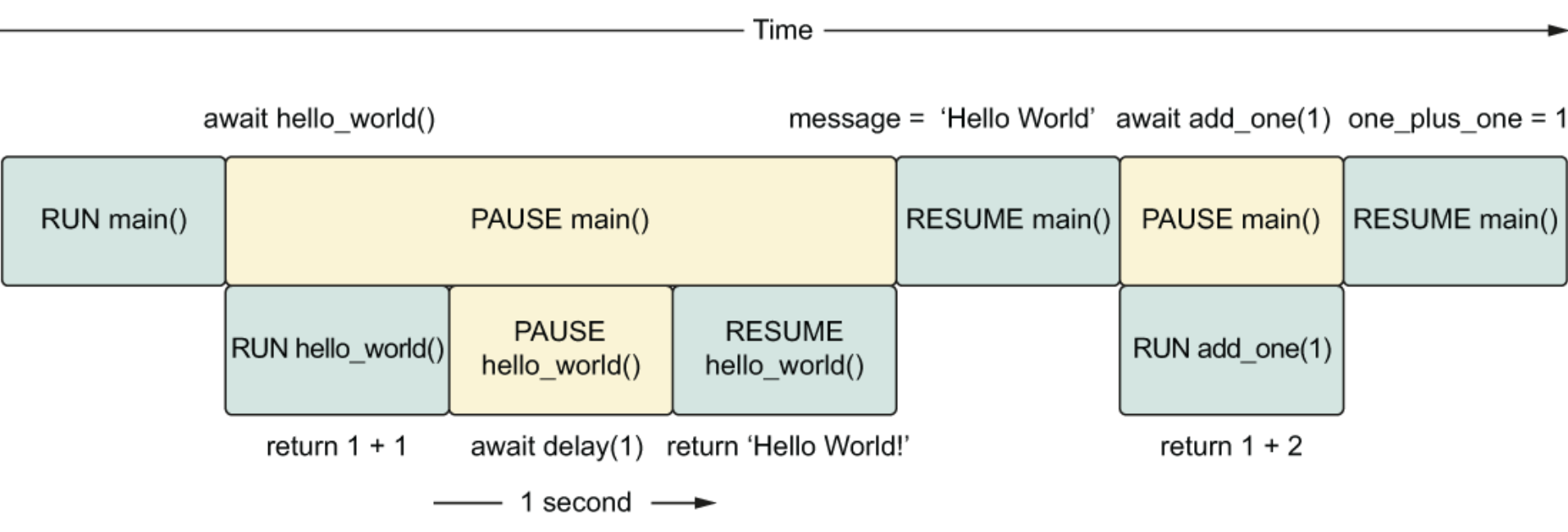
asyncio.sleep asyncio.sleep本身就是一个协程,因此我们必须使用await关键字来调用它。如果我们仅仅调用它本身,我们将会得到一个协程对象。由于asyncio.sleep是一个协程,这意味着当一个协程等待它时,其他的代码会被执行。
1 2 3 4 5 6 7 8 9 10 11 import asyncio async def hello_world_message () -> str: await asyncio.sleep(1 ) return "Hello World!" async def main () -> None : message = hello_world_message() print(message) asyncio.run(main())
任务 下面的 delay 是自己封装的 asyncio.sleep 方法。
1 2 3 4 5 6 7 import asyncioasync def delay (delay_seconds: int) -> int: print(f'sleeping for {delay_seconds} second(s)' ) await asyncio.sleep(delay_seconds) print(f'finished sleeping for {delay_seconds} second(s)' ) return delay_seconds
两个协程示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import asynciofrom util import delay async def add_one (number: int) -> int: return number + 1 async def hello_world () -> str: await delay(1 ) return "Hello World!" async def main () -> None : message = await hello_world() one_plus_one = await add_one(1 ) print(one_plus_one) print(message) asyncio.run(main())
当我们运行此代码时,需要等待1秒钟才会打印出两个函数调用的结果。因为 await 使我们的当前协程暂停,并且在 await 表达式给出一个值之前,不会执行协程中的任何其他代码。由于需要1秒钟才能让 hello_world 函数给我们一个值,因此主协程会暂停1秒钟。这种情况下,我们的代码的行为就如同是顺序执行的。
任务 是协程的包装器,可以调度协程尽快在事件循环上运行。此调度和执行以非阻塞方式进行,意味着一旦我们创建任务,我们可以在任务运行时立即执行其他代码。这与使用 await 关键字形成对比,await 以阻塞方式运行,意味着我们暂停整个协程,直到 await 表达式的结果返回。
创建任务可以通过使用 asyncio.create_task 函数来实现。当我们调用此函数时,我们将协程传递给它运行,它会立即返回一个任务对象。一旦我们有了一个任务对象,我们就可以将它放在一个等待表达式中,在任务完成时提取返回值。
1 2 3 4 5 6 7 8 9 10 11 import asynciofrom util import delay async def main () : sleep_for_three = asyncio.create_task(delay(3 )) print(type(sleep_for_three)) result = await sleep_for_three print(result) asyncio.run(main())
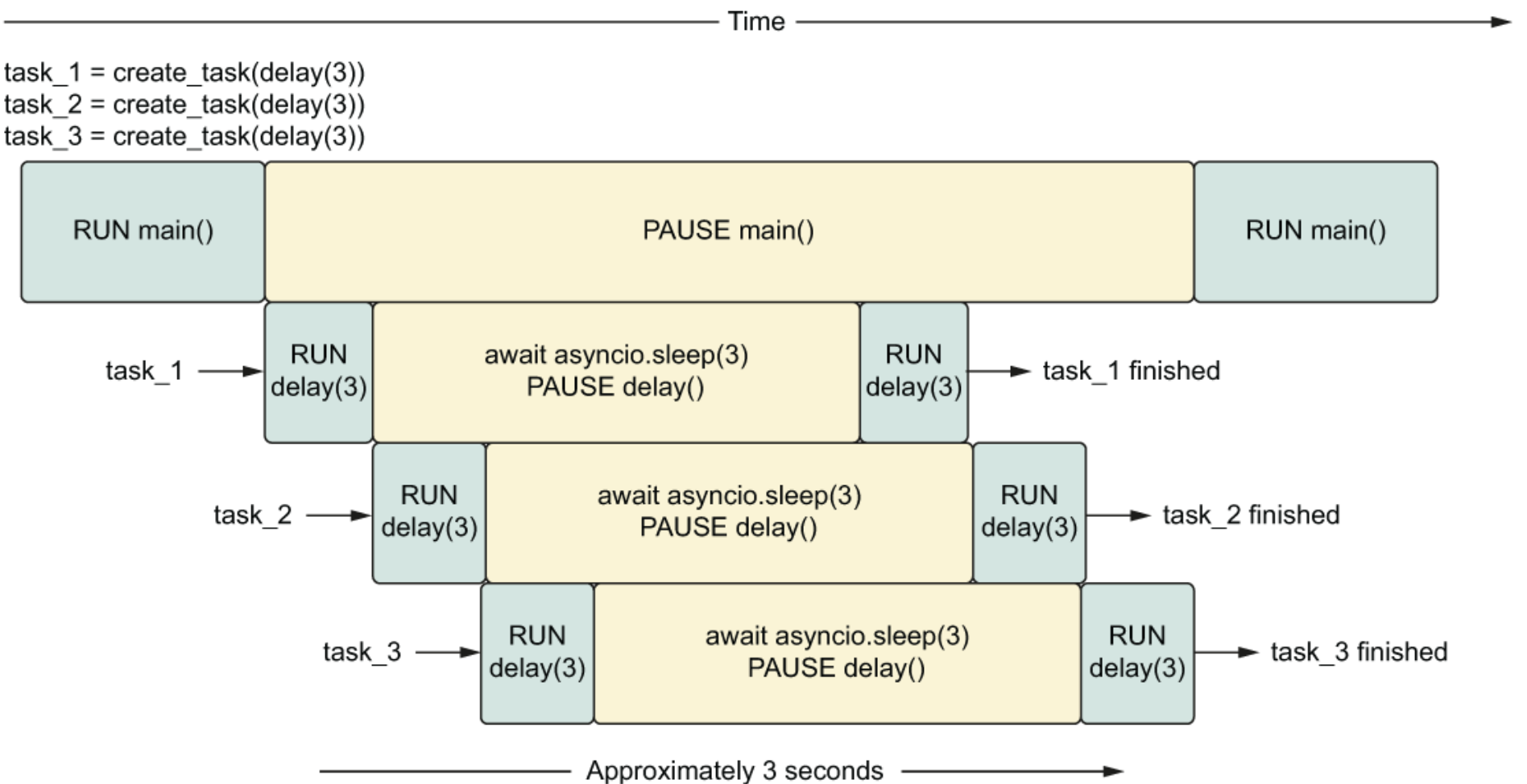
运行多个任务 示例一:
1 2 3 4 5 6 7 8 9 10 11 12 13 import asynciofrom util import delayasync def main () : sleep_for_three = asyncio.create_task(delay(3 )) sleep_again = asyncio.create_task(delay(3 )) sleep_once_more = asyncio.create_task(delay(3 )) await sleep_for_three await sleep_again await sleep_once_more asyncio.run(main())
我们启动了三个任务,每个任务花费3秒钟来完成。每次调用 create_task 都会立即返回,所以我们很快进入 await sleep_for_three 语句。在创建任务后第一次遇到 await 语句时,任何待处理的任务都会随着 await 触发事件循环的迭代而运行。
所以从 await sleep_for_three 开始,所有三个任务开始运行并将同时进行任何睡眠操作。这意味着上面代码约在 3s 左右完成。
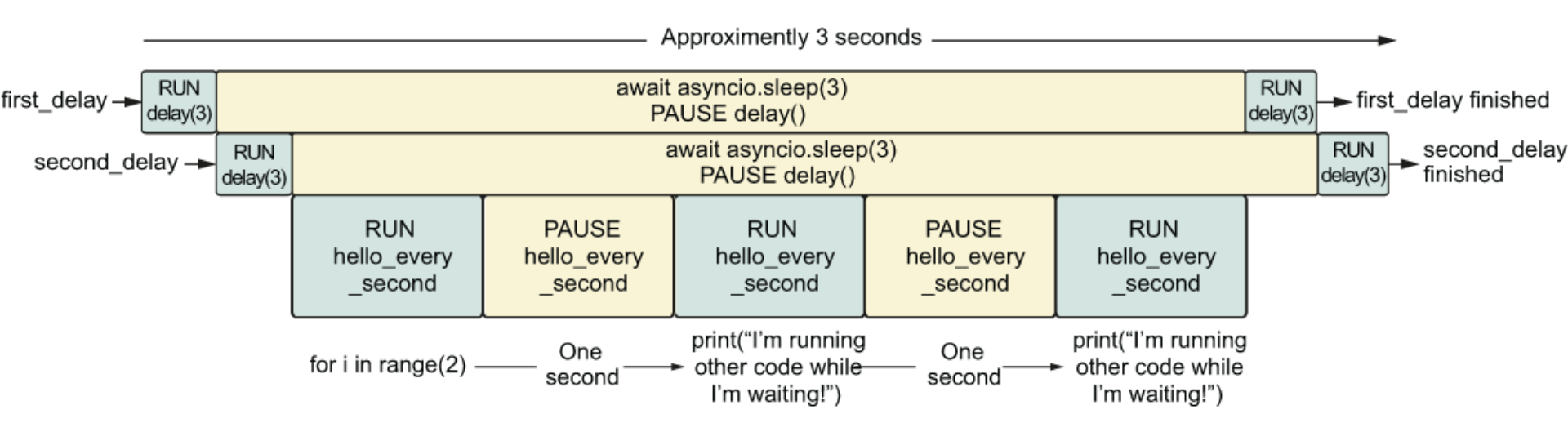
示例二:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import asynciofrom util import delayasync def hello_every_second () : for i in range(2 ): await asyncio.sleep(1 ) print("I'm running other code while I'm waiting!" ) async def main () : first_delay = asyncio.create_task(delay(3 )) second_delay = asyncio.create_task(delay(3 )) await hello_every_second() await first_delay await second_delay """ sleeping for 3 second(s) sleeping for 3 second(s) I'm running other code while I'm waiting! I'm running other code while I'm waiting! finished sleeping for 3 second(s) finished sleeping for 3 second(s) """
上述代码中创建了两个任务,每个任务需要3秒钟才能完成。当这些任务在等待时,我们的应用程序处于空闲状态,这给了我们运行其他代码的机会。在这种情况下,我们运行一个名为 hello_every_second 的协程,它每秒钟打印一次消息,共打印2次。
取消任务 取消任务很简单。每个任务对象都有一个叫做 cancel 的方法,我们可以在任何时候调用它来停止任务。取消任务将导致该任务在我们等待它时引发一个 CancelledError。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import asynciofrom asyncio import CancelledErrorfrom util import delay async def main () : long_task = asyncio.create_task(delay(10 )) seconds_elapsed = 0 while not long_task.done(): print('Task not finished, checking again in a second.' ) await asyncio.sleep(1 ) seconds_elapsed = seconds_elapsed + 1 if seconds_elapsed == 5 : long_task.cancel() try : await long_task except CancelledError: print('Our task was cancelled' ) asyncio.run(main())
上述我们创建了一个需要运行10秒的任务。然后,我们创建了一个 while 循环来检查该任务是否完成。任务上的done方法会在任务完成时返回 True,否则返回False。每秒钟,我们都会检查任务是否完成,记录已经检查了多少秒。如果任务已经进行了5秒钟,我们将取消该任务。然后,我们将进行等待 long_task,并且我们将看到打印出 Our task was cancelled,表示我们已经捕获了 CancelledError。
设置超时时间 超时后任务被取消 asyncio.wait_for 函数接受一个协程或任务对象,以及以秒为单位指定的超时。然后它返回一个我们可以等待的协程。如果完成任务所需的时间比我们指定的超时时间长,则会引发 TimeoutException。一旦达到超时阈值,任务将自动取消。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 import asynciofrom util import delay async def main () : delay_task = asyncio.create_task(delay(2 )) try : result = await asyncio.wait_for(delay_task, timeout=1 ) print(result) except asyncio.exceptions.TimeoutError: print('Got a timeout!' ) print(f'Was the task cancelled? {delay_task.cancelled()} ' ) asyncio.run(main()) """ sleeping for 2 second(s) Got a timeout! Was the task cancelled? True """
超时后任务不取消 调用 wait_for 并将任务包装在 shield 中,这将防止任务被取消。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import asynciofrom util import delay async def main () : task = asyncio.create_task(delay(10 )) try : result = await asyncio.wait_for(asyncio.shield(task), 5 ) print(result) except TimeoutError: print("任务已超时,但不会停止运行!" ) result = await task print(result) asyncio.run(main()) """ sleeping for 10 second(s) 任务已超时,但不会停止运行! finished sleeping for 10 second(s) finished <function delay at 0x10e8cf820> in 10 second(s) """
future future 是一个 Python 对象,其中包含您期望在未来某个时刻获得但可能尚未获得的单个值。通常,当你创建一个 future 时,它没有任何价值,因为它还不存在。在这种状态下,它被认为是不完整的、未解决的或根本没有完成。我们可以设定 future 的值。到那时,我们就可以认为它完成了,并从 future 提取结果。
1 2 3 4 5 6 7 8 9 10 from asyncio import Future my_future = Future() print(f'Is my_future done? {my_future.done()} ' ) my_future.set_result(42 ) print(f'Is my_future done? {my_future.done()} ' ) print(f'What is the result of my_future? {my_future.result()} ' )
Future 也可以用在 await 表达式中。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 from asyncio import Futureimport asynciodef make_request () -> Future: future = Future() asyncio.create_task(set_future_value(future)) return future async def set_future_value (future) -> None : await asyncio.sleep(1 ) future.set_result(42 ) async def main () : future = make_request() print(f"Is the future done? {future.done()} " ) value = await future print(f"Is the future done? {future.done()} " ) print(value) asyncio.run(main()) """ Is the future done? False Is the future done? True 42 """
上述代码在 make_request 中创建了一个 future,并将其传入到了 task 中,然后在 set_future_value 中进行 future 值的设置。可以使用 future.done() 的来获取 future 的状态。
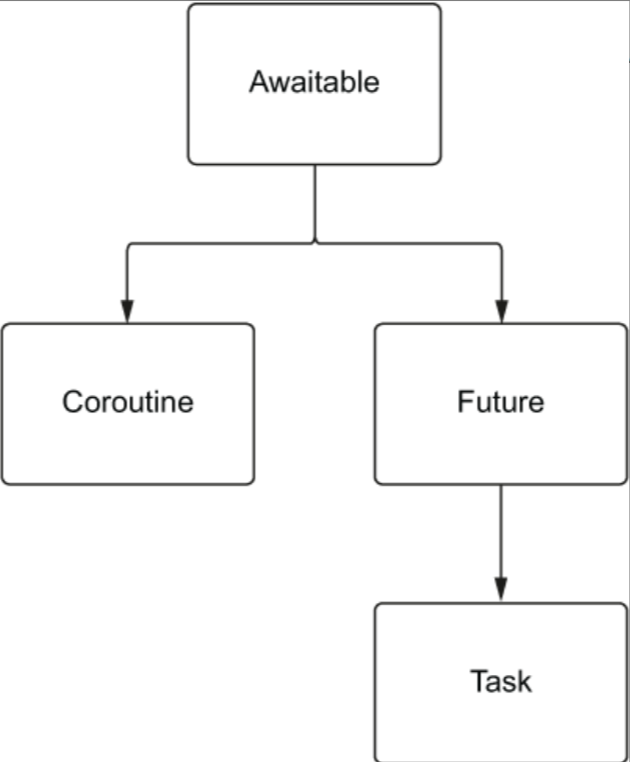
Awaitable task 和 future 之间存在着密切的关系,task 直接继承自 future。当我们创建一个 task 时,可以理解为正在创建一个空的 future 并运行协程。然后,当协程完成并出现异常或结果时,在将值设置到 future 中。
这些类型都可以在await 表达式中使用?但是任何实现__await__方法的东西都可以在等待表达式中使用。协程直接继承自 Awaitable,future 也是如此。然后 task 继承自 future。
协程装饰器 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import functoolsimport timefrom typing import Callable, Anydef async_timed () : def wrapper (func: Callable) -> Callable: @functools.wraps(func) async def wrapped (*args, **kwargs) -> Any: print(f'starting {func} with args {args} {kwargs} ' ) start = time.time() try : return await func(*args, **kwargs) finally : end = time.time() total = end - start print(f'finished {func} in {total:.4 f} second(s)' ) return wrapped return wrapper
使用示例:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import asyncio@async_timed() async def delay (delay_seconds: int) -> int: print(f'sleeping for {delay_seconds} second(s)' ) await asyncio.sleep(delay_seconds) print(f'finished sleeping for {delay_seconds} second(s)' ) return delay_seconds @async_timed() async def main () : task_one = asyncio.create_task(delay(2 )) task_two = asyncio.create_task(delay(3 )) await task_one await task_two asyncio.run(main()) """ starting <function main at 0x109111ee0> with args () {} starting <function delay at 0x1090dc700> with args (2,) {} starting <function delay at 0x1090dc700> with args (3,) {} finished <function delay at 0x1090dc700> in 2.0032 second(s) finished <function delay at 0x1090dc700> in 3.0003 second(s) finished <function main at 0x109111ee0> in 3.0004 second(s) """
两种错误的异步场景 将CPU密集型任务运行在协程中 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import asynciofrom util import delay @async_timed() async def cpu_bound_work () -> int: counter = 0 for i in range(100000000 ): counter = counter + 1 return counter @async_timed() async def main () : task_one = asyncio.create_task(cpu_bound_work()) task_two = asyncio.create_task(cpu_bound_work()) await task_one await task_two asyncio.run(main()) """ starting <function main at 0x10a8f6c10> with args () {} starting <function cpu_bound_work at 0x10a8c0430> with args () {} finished <function cpu_bound_work at 0x10a8c0430> in 4.6750 second(s) starting <function cpu_bound_work at 0x10a8c0430> with args () {} finished <function cpu_bound_work at 0x10a8c0430> in 4.6680 second(s) finished <function main at 0x10a8f6c10> in 9.3434 second(s) """
尽管上述代码创建了两个任务,但我们的代码仍然按顺序执行。首先,我们运行 task_one,然后运行 task_two,这意味着我们的总运行时间将是对 cpu_bound_work 的两次调用的总和。
下面代码也存在同样的问题:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import asynciofrom util import async_timed, delay @async_timed() async def cpu_bound_work () -> int: counter = 0 for i in range(100000000 ): counter = counter + 1 return counter @async_timed() async def main () : task_one = asyncio.create_task(cpu_bound_work()) task_two = asyncio.create_task(cpu_bound_work()) delay_task = asyncio.create_task(delay(4 )) await task_one await task_two await delay_task asyncio.run(main())
为什么会出现这样的现象呢?因为我们首先创建了两个 CPU 密集型任务,这实际上阻止了事件循环运行其他任何任务。这将导致我们的任务会按照顺序执行。
如果我们需要执行 CPU 密集型工作并且仍然想使用 async/await 语法。 那么我们需要将 asyncio 和进程池进行结合使用。
使用阻塞的 I/O 操作 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import asyncioimport requestsfrom util import async_timed @async_timed() async def get_example_status () -> int: return requests.get('http://www.example.com' ).status_code @async_timed() async def main () : task_1 = asyncio.create_task(get_example_status()) task_2 = asyncio.create_task(get_example_status()) task_3 = asyncio.create_task(get_example_status()) await task_1 await task_2 await task_3 asyncio.run(main()) """ starting <function main at 0x1102e6820> with args () {} starting <function get_example_status at 0x1102e6700> with args () {} finished <function get_example_status at 0x1102e6700> in 0.0839 second(s) starting <function get_example_status at 0x1102e6700> with args () {} finished <function get_example_status at 0x1102e6700> in 0.0441 second(s) starting <function get_example_status at 0x1102e6700> with args () {} finished <function get_example_status at 0x1102e6700> in 0.0419 second(s) finished <function main at 0x1102e6820> in 0.1702 second(s) """
上述代码中,主协程的总运行时间大致是所有任务运行的时间总和,这意味着我们没有任何并发优势。
为什么会这样呢?这是因为 request 库不返回协程,是一个阻塞的API。在上面的示例中,我们可以使用 aiohttp 等库来替换 request。如果不想换库,就是需要使用 requests 库,我们仍然可以使用 async 语法,但需要显式告诉 asyncio 使用线程池来执行。
事件循环 目前,我们已经使用 asyncio.run 来运行我们的应用程序并在幕后为我们创建事件循环。我们还有其他方式可以创建事件循环。
1 2 3 4 5 6 7 8 9 10 11 import asyncioasync def main () : await asyncio.sleep(1 ) loop = asyncio.new_event_loop() try : loop.run_until_complete(main()) finally : loop.close()
我们还可以获取当前的事件循环:
1 2 3 4 5 6 7 8 9 10 11 import asyncio def call_later () : print("I'm being called in the future!" ) async def main () : loop = asyncio.get_running_loop() loop.call_soon(call_later) await delay(1 ) asyncio.run(main())
除了 asyncio.get_running_loop 函数可以获取事件循环外,另一个函数 asyncio.get_event _loop 也可以。区别在于如果在事件循环未运行期间调用 asyncio.get_event _loop,则会创建一个新的事件循环,这样可能会导致一些奇怪的问题。所以建议使用 asyncio.get_running_loop 来获取当前的事件循环。
调试模式 方式一:
1 asyncio.run(coroutine(), debug=True )
方式二:
1 python3 -X dev program.py
方式三:
1 PYTHONASYINCIODEBUG=1 python3 program.py
在早于 3.9 的 Python 版本中, 使用 asyncio.run 时,只有 debug 参数才有效。命令行参数和环境变量仅在手动管理事件循环时才起作用。
例如在 CPU 密集型操作中,如果协程花费的时间太长,我们在 debug 模式下将会看到一些信息:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 import asynciofrom util import async_timed @async_timed() async def cpu_bound_work () -> int: counter = 0 for i in range(100000000 ): counter = counter + 1 return counter async def main () -> None : task_one = asyncio.create_task(cpu_bound_work()) await task_one asyncio.run(main(), debug=True ) """ Executing <Task finished name='Task-2' coro=<cpu_bound_work() done, defined at D:\project\autoexpense\aaaa.py:4> result=100000000 created at C:\Users\hongji\.conda\envs\3.10\lib\asyncio\tasks.py:337> took 3.984 seconds """
默认时间超过 100ms 就会出现上述提示,我们可以更改这个提示的时间,例如将其改为 250 毫秒。
1 2 3 4 5 6 7 import asyncioasync def main () : loop = asyncio.get_event_loop() loop.slow_callback_duration = .250 asyncio.run(main(), debug=True )
第四章 异步上下文 异步上下文管理器是实现两个特殊协程方法的类:__aenter__用于异步获取资源,__aexit__用于关闭该资源。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import asyncioclass AsyncContextManager : async def __aenter__ (self) : print("进入上下文管理器" ) await asyncio.sleep(1 ) return "进入上下文管理器成功" async def __aexit__ (self, exc_type, exc_value, traceback) : print("离开上下文管理器" ) await asyncio.sleep(1 ) if exc_type is not None : print(f"发生异常:{exc_type} , {exc_value} , {traceback} " ) else : print("没有发生异常" ) async def main () : async with AsyncContextManager() as result: print(result) asyncio.run(main())
aiohttp 默认情况下ClientSession将创建最多100个连接
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 import asyncioimport aiohttpfrom aiohttp import ClientSessionfrom util import async_timed@async_timed() async def fetch_status (session: ClientSession, url: str) -> int: async with session.get(url) as result: return result.status @async_timed() async def main () : async with aiohttp.ClientSession() as session: url = 'https://www.example.com' status = await fetch_status(session, url) print(f'Status for {url} was {status} ' ) asyncio.run(main()) """ 开始执行函数 main 参数: () {} 开始执行函数 fetch_status 参数: (<aiohttp.client.ClientSession object at 0x7fbdd40e9e70>, 'https://www.example.com') {} 完成执行函数 fetch_status 花费 0.9957 秒(s) Status for https://www.example.com was 200 完成执行函数 main 花费 0.9963 秒(s) """
设置超时时间
超时时间可以在 session 会话上设置,也可以在每个 session 发起请求的时候设置。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import asyncioimport aiohttpfrom aiohttp import ClientSessionasync def fetch_status (session: ClientSession, url: str) -> int: ten_millis = aiohttp.ClientTimeout(total=.01 ) async with session.get(url, timeout=ten_millis) as result: return result.status async def main () : session_timeout = aiohttp.ClientTimeout(total=1 , connect=.1 ) async with aiohttp.ClientSession(timeout=session_timeout) as session: await fetch_status(session, 'https://baidu.com' ) asyncio.run(main())
列表推导式下的并发 ❌不正确的做法
1 2 3 4 5 6 7 8 9 10 import asynciofrom util import async_timed, delay @async_timed() async def main () -> None : delay_times = [3 , 3 , 3 ] [await asyncio.create_task(delay(seconds)) for seconds in delay_times] asyncio.run(main())
理想情况下希望任务并发运行,我们期望主方法大约在3秒内完成。然而,在这种情况下,由于所有事情都是依次完成的,需要花费9秒钟来运行。
这是因为我们在创建任务时就使用了 await。这意味着我们会暂停列表推导和主协程,直到我们创建的每个延迟任务完成。在这种情况下,我们每次只会运行一个任务,而不是同时运行多个任务。
✅正确的做法
1 2 3 4 5 6 7 8 9 10 import asynciofrom util import async_timed, delay @async_timed() async def main () -> None : delay_times = [3 , 3 , 3 ] tasks = [asyncio.create_task(delay(seconds)) for seconds in delay_times] [await task for task in tasks] asyncio.run(main())
这种情况下 create_task会立即返回,直到所有任务都被创建后才会等待它们运行完成。
gather 上述列表推导式的写法存在一些问题:
它由多行代码组成,我们必须明确地记住将任务创建与等待分开
不够灵活,如果我们的某个协程比其他协程早完成,我们将被困在第二个列表的运行中,等待所有其他协程完成。
最大的问题是异常处理。如果我们的某个协程有异常,如果将错误抛出,意味着我们将无法处理任何成功完成的任务,因为其中一个异常将停止我们的执行。
gather 函数接受一个 awaitable 序列,可以在一行代码中同时运行它们。如果我们传递的任何 awaitable 是一个协程,gather 将自动将其包装在任务中以确保其并发运行。这意味着我们不必像上面那样分别使用 asyncio.create_task 来进行包装。
asyncio.gather 返回一个可等待对象。当我们在 await 表达式中使用它时。它将暂停,直到我们传递给它的所有可等待对象都完成为止。一旦我们传递的所有对象都完成了,asyncio.gather 将返回已完成结果的列表。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import asyncioimport aiohttpfrom util import fetch_statusfrom util import async_timed@async_timed() async def main () : async with aiohttp.ClientSession() as session: urls = ['https://baidu.com' for _ in range(1000 )] requests = [fetch_status(session, url) for url in urls] status_codes = await asyncio.gather(*requests) print(status_codes) asyncio.run(main()) """ ... 完成执行函数 main 花费 6.2282 秒(s) """
gather的一个好处是,无论我们的可等待对象何时完成,我们都保证结果会按照我们传递它们的顺序返回
如果是采用同步的方式,如下所示,那将会很耗时
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import asyncioimport aiohttpfrom util import async_timed, fetch_status@async_timed() async def main () : async with aiohttp.ClientSession() as session: urls = ['https://baidu.com' for _ in range(1000 )] status_codes = [await fetch_status(session, url) for url in urls] print(status_codes) asyncio.run(main()) """ ... 完成执行函数 main 花费 60.4100 秒(s) """
gather 中的异常
asyncio.gather 给我们提供了一个可选参数 return_exceptions,是一个布尔值,它允许我们指定如何处理来自awaitable的异常。
True: gather 将会在我们 await 它时将任何异常作为结果列表的一部分返回。gather 的调用本身不会抛出任何异常,我们将能够根据自己的意愿处理所有异常。
False: 默认值。在这种情况下,如果我们的任一协程引发异常,当我们 await 它时,我们的 gather 调用也会抛出该异常。然而,即使其中一个协程失败了,我们的其他协程也不会被取消,只要我们处理异常或异常不会导致事件循环停止和取消任务,它们就会继续运行。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 import asyncioimport aiohttpfrom util import fetch_status, async_timed@async_timed() async def main () : async with aiohttp.ClientSession() as session: urls = ['python://example.com' , 'https://baidu.com' ] tasks = [fetch_status(session, url) for url in urls] status_codes = await asyncio.gather(*tasks) print(status_codes) asyncio.run(main())
上述代码会发生异常,但是能正确的请求百度。
当 return_exceptions 默认为 False 的时候存在一个问题,那就是如果发生多个异常,我们只能看到在等待gather时发生的第一个异常。我们可以通过使用 return_exceptions=True 来解决这个问题,这将返回我们在运行协程时遇到的所有异常。然后我们可以过滤掉任何异常并根据需要处理它们。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import asyncioimport aiohttpfrom util import async_timed, fetch_status@async_timed() async def main () : async with aiohttp.ClientSession() as session: urls = ['https://baidu.com' , 'python://example.com' ] tasks = [fetch_status(session, url) for url in urls] results = await asyncio.gather(*tasks, return_exceptions=True ) exceptions = [res for res in results if isinstance(res, Exception)] successful_results = [res for res in results if not isinstance(res, Exception)] print(f'All results: {results} ' ) print(f'Finished successfully: {successful_results} ' ) print(f'Threw exceptions: {exceptions} ' ) asyncio.run(main()) """ 开始执行函数 main 参数: () {} 开始执行函数 fetch_status 参数: (<aiohttp.client.ClientSession object at 0x7f7fa1264220>, 'https://baidu.com') {} 开始执行函数 fetch_status 参数: (<aiohttp.client.ClientSession object at 0x7f7fa1264220>, 'python://example.com') {} 完成执行函数 fetch_status 花费 0.0003 秒(s) 完成执行函数 fetch_status 花费 0.2335 秒(s) All results: [200, AssertionError()] Finished successfully: [200] Threw exceptions: [AssertionError()] 完成执行函数 main 花费 0.2343 秒(s) """
as_completed asyncio.gather()存在一些缺点,即在允许访问任何结果之前,它会等待所有协程完成。如果我们想要在接收到结果后立即处理结果,这就是一个问题。如果我们有一些协程可能会很快完成,而另一些协程可能需要一些时间,因为gather()会等待所有任务完成。
asyncio 暴露了一个名为 as_completed 的API函数。这个方法接受一个可等待对象列表并返回一个 future 的迭代器。然后我们可以遍历这些 future,并等待结果返回。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import asyncioimport aiohttpfrom aiohttp import ClientSessionfrom util import async_timed@async_timed() async def request (session: ClientSession, url: str, delay: int = 0 ) -> int: await asyncio.sleep(delay) async with session.get(url) as result: return result.status @async_timed() async def main () : async with aiohttp.ClientSession() as session: fetchers = [ request(session, 'https://baidu.com' , 1 ), request(session, 'https://baidu.com' , 1 ), request(session, 'https://baidu.com' , 3 ) ] for finished_task in asyncio.as_completed(fetchers): print(await finished_task) asyncio.run(main()) """ 开始执行函数 main 参数: () {} 开始执行函数 request 参数: (<aiohttp.client.ClientSession object at 0x7fd820268280>, 'https://baidu.com', 1) {} 开始执行函数 request 参数: (<aiohttp.client.ClientSession object at 0x7fd820268280>, 'https://baidu.com', 1) {} 开始执行函数 request 参数: (<aiohttp.client.ClientSession object at 0x7fd820268280>, 'https://baidu.com', 3) {} 完成执行函数 request 花费 1.2250 秒(s) 200 完成执行函数 request 花费 1.2322 秒(s) 200 完成执行函数 request 花费 3.0688 秒(s) 200 完成执行函数 main 花费 3.0698 秒(s) """
上述代码中,在背后,每个协程被包装在一个 task 中,并开始并发运行。该协程立即返回一个迭代器开始循环。当我们进入 for 循环时,我们碰到了 await finished_task。在这里我们暂停执行并等待我们的第一个结果。在这种情况下,我们的第一个结果在1秒钟后到达,并打印状态码。然后我们再次到达 await finished_task,由于我们的请求同时运行,我们应该几乎立即看到第二个结果。最后,我们的3秒钟的请求将完成,我们的循环将结束。
这个函数还可以更好地控制异常处理。当一个任务抛出异常时,我们可以在它发生时处理它,因为该异常在我们 awit feture 时抛出。
as_completed 超时控制
as_completed 函数通过提供一个可选的超时参数来支持此用例,我们可以指定一个以秒为单位的超时时间。这将跟踪 as_completed 调用所花费的时间;如果它花费的时间超过超时时间,那么迭代器中的每个 awaitable 在我们await 它时都会抛出一个TimeoutException。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 import asyncioimport aiohttpfrom aiohttp import ClientSessionfrom util import async_timed@async_timed() async def request (session: ClientSession, url: str, delay: int = 0 ) -> int: await asyncio.sleep(delay) async with session.get(url) as result: return result.status @async_timed() async def main () : async with aiohttp.ClientSession() as session: fetchers = [ request(session, 'https://baidu.com' , 1 ), request(session, 'https://baidu.com' , 1 ), request(session, 'https://baidu.com' , 5 ) ] for done_task in asyncio.as_completed(fetchers, timeout=2 ): try : result = await done_task print(result) except asyncio.TimeoutError: print('获取到一个超时错误!' ) for task in asyncio.tasks.all_tasks(): print(task) asyncio.run(main()) """ 开始执行函数 main 参数: () {} 开始执行函数 request 参数: (<aiohttp.client.ClientSession object at 0x7faa57320610>, 'https://baidu.com', 1) {} 开始执行函数 request 参数: (<aiohttp.client.ClientSession object at 0x7faa57320610>, 'https://baidu.com', 5) {} 开始执行函数 request 参数: (<aiohttp.client.ClientSession object at 0x7faa57320610>, 'https://baidu.com', 1) {} 完成执行函数 request 花费 1.2148 秒(s) 200 完成执行函数 request 花费 1.2217 秒(s) 200 获取到一个超时错误! <Task pending name='Task-3' coro=<request() ... # 一个请求仍在运行 <Task pending name='Task-1' coro=<main() ... 完成执行函数 main 花费 2.0010 秒(s) 完成执行函数 request 花费 2.0010 秒(s) """
上述代码中,我们将看到一个超时错误。我们还将看到一个请求仍在运行。
wait as_completed 对于尽快获取结果而言效果很好,但有一些缺点。首先,顺序是完全不确定的,因此无法轻松查看我们正在等待的哪个协程或任务。如果我们不关心顺序,这可能是可以接受的。
第二个问题是,使用超时时,虽然我们会正确地抛出异常并继续执行,但任何创建的任务仍然会在后台运行。
wait 方法有几个选项可供选择,取决于我们想要何时获得结果。此外,此方法返回两个集合:一个已完成的任务集合(包含结果集或异常集),以及一个当前运行的任务集合。该函数还允许我们指定超时时间,其行为与其他API方法运行方式不同;它不会抛出异常。
wait 方法的基本签名是一个可等待项目列表,后跟可选的超时和可选的 return_when 字符串。该字符串有几个预定义的值:
ALL_COMPLETED:默认值,将等待所有任务完成后才返回
FIRST_EXCEPTION:遇到第一个异常就返回
FIRST_COMPLETED:运行完第一个任务就返回
在处理错误方面,我们可以将 await 放在 try except 块中来处理异常,或者我们可以使用 task.result() 和task.exception() 方法,来获取结果和异常。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 import asyncioimport loggingimport aiohttpfrom util import fetch_status, async_timed@async_timed() async def main () : async with aiohttp.ClientSession() as session: good_request = fetch_status(session, 'https://baidu.com' ) bad_request = fetch_status(session, 'python://bad' ) fetchers = [ asyncio.create_task(good_request), asyncio.create_task(bad_request) ] done, pending = await asyncio.wait(fetchers) print(f'已完成的任务数量: {len(done)} ' ) print(f'阻塞的任务数量: {len(pending)} ' ) for done_task in done: if done_task.exception() is None : print(done_task.result()) else : logging.error("请求异常" , exc_info=done_task.exception()) asyncio.run(main()) """ 开始执行函数 main 参数: () {} 开始执行函数 fetch_status 参数: (<aiohttp.client.ClientSession object at 0x7f8aa3c6c250>, 'https://baidu.com') {} 开始执行函数 fetch_status 参数: (<aiohttp.client.ClientSession object at 0x7f8aa3c6c250>, 'python://bad') {} 完成执行函数 fetch_status 花费 0.0003 秒(s) 完成执行函数 fetch_status 花费 0.2308 秒(s) 已完成的任务数量: 2 阻塞的任务数量: 0 200 完成执行函数 main 花费 0.2345 秒(s) ERROR:root:请求异常 Traceback (most recent call last): ... packages/aiohttp/connector.py", line 1144, in _create_direct_connection assert port is not None AssertionError """
监听异常
FIRST_EXCEPTION ,如果所有任务都没有发生异常,则此选项等同于ALL_COMPLETED,如果有任何任务抛出异常,wait 将立即返回一旦异常被抛出。done 集将包含任何成功完成的协程以及任何带有异常的协程。在这种情况下,done 集保证至少有一个失败的任务,但可能还有成功完成的任务。挂起的集合可能为空,但也可能有仍在运行的任务。
异常情况下取消正在运行的任务:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import asyncioimport loggingimport aiohttpfrom util import async_timed, fetch_status@async_timed() async def main () : async with aiohttp.ClientSession() as session: fetchers = [ asyncio.create_task(fetch_status(session, 'python://bad.com' )), asyncio.create_task(fetch_status(session, 'https://www.baidu.com' , delay=3 )), asyncio.create_task(fetch_status(session, 'https://www.baidu.com' , delay=3 )) ] done, pending = await asyncio.wait(fetchers, return_when=asyncio.FIRST_EXCEPTION) print(f'已完成的任务数量: {len(done)} ' ) print(f'阻塞的任务数量: {len(pending)} ' ) for done_task in done: if done_task.exception() is None : print(done_task.result()) else : logging.error("请求异常" , exc_info=done_task.exception()) for pending_task in pending: print(f"取消任务: {pending_task} " ) pending_task.cancel() asyncio.run(main())
逐个处理结果
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import asyncioimport aiohttpfrom util import async_timed, fetch_status@async_timed() async def main () : async with aiohttp.ClientSession() as session: url = 'https://www.baidu.com' pending = [ asyncio.create_task(fetch_status(session, url)), asyncio.create_task(fetch_status(session, url)), asyncio.create_task(fetch_status(session, url, delay=3 )) ] while pending: done, pending = await asyncio.wait(pending, return_when=asyncio.FIRST_COMPLETED) print(f'完成任务数量: {len(done)} ' ) print(f'阻塞任务数量: {len(pending)} ' ) for done_task in done: print(await done_task) asyncio.run(main()) """ 完成任务数量: 1 阻塞任务数量: 2 200 完成执行函数 fetch_status 花费 0.1010 秒(s) 完成任务数量: 1 阻塞任务数量: 1 200 完成执行函数 fetch_status 花费 3.0169 秒(s) 完成任务数量: 1 阻塞任务数量: 0 200 """
上述代码中使用 while 循环 pending,直到 pending 为空。然后再次更新完成的任务和阻塞中的任务。依次在 for 循环中循环已完成的任务,然后获取结果。
超时处理
wait 中的超时与我们迄今为止所看到的 wait_for 和 as_completed 不同:
当我们使用 wait_for 时,如果我们的协程超时,它会自动请求取消。但 wait 并不是这种情况,它的行为更接近于我们在 gather 和 as_completed 中看到的方法。如果我们想由于超时而取消协程,我们必须显式地遍历这些任务并将它们取消。
wait 不像 wait_for 和 as_completed,wait 超时不会被引发错误。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import asyncioimport aiohttpfrom util import async_timed, fetch_status@async_timed() async def main () : async with aiohttp.ClientSession() as session: url = 'https://baidu.com' fetchers = [ asyncio.create_task(fetch_status(session, url)), asyncio.create_task(fetch_status(session, url)), asyncio.create_task(fetch_status(session, url, delay=3 )) ] done, pending = await asyncio.wait(fetchers, timeout=1 ) print(f'Done task count: {len(done)} ' ) print(f'Pending task count: {len(pending)} ' ) for done_task in done: result = await done_task print(result) asyncio.run(main()) """ 开始执行函数 main 参数: () {} 开始执行函数 fetch_status 参数: ... 开始执行函数 fetch_status 参数: ... 开始执行函数 fetch_status 参数: ... 完成执行函数 fetch_status 花费 0.2293 秒(s) 完成执行函数 fetch_status 花费 0.2010 秒(s) Done task count: 2 Pending task count: 1 200 完成执行函数 main 花费 1.0023 秒(s) 完成执行函数 fetch_status 花费 0.9705 秒(s) """
pending 待处理任务集中的任务并未被取消,并且尽管超时仍将继续运行。如果我们希望终止待处理任务,则需要显式遍历待处理集,并在每个任务上调用取消操作来手工取消。
传递给 wait 和协程最好包装在 tasks 中
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import asyncioimport aiohttpfrom util import fetch_statusasync def main () : async with aiohttp.ClientSession() as session: api_a = fetch_status(session, 'https://www.baidu.com' ) api_b = fetch_status(session, 'https://www.baidu.com' , delay=2 ) done, pending = await asyncio.wait([api_a, api_b], timeout=1 ) for task in pending: if task is api_b: print('API B too slow, cancelling' ) task.cancel() asyncio.run(main())
原因是在我们将协程传递给 wait 函数时,每个协程会被自动转换为 task(创建一个 新的 task 对象)。这样在进行 is 比较的时候就会是 false,所以没有得到期待的结果。所以推荐的做法是使用 asyncio.create_task 方法将其包一层。
第六章 全局解释器锁防止多个 Python 字节代码并行运行。这意味着对于除了 I/O 绑定任务以外的任何东西,大多数使用多线程并不会带来任何性能优势。
我们可以不使用父进程生成线程来并行处理任务,而是生成子进程来处理我们的工作。每个子进程都将有自己的Python解释器,并受到GIL的控制,但是我们将有多个解释器,每个解释器都有自己的GIL。这意味着我们可以有效地并行处理任何CPU密集型工作负载。即使我们的进程数多于核心数,我们的操作系统也将使用抢占式多任务处理,以允许我们的多个任务并发运行。
多进程示例 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import timefrom multiprocessing import Processdef count (count_to: int) -> int: start = time.time() counter = 0 while counter < count_to: counter = counter + 1 end = time.time() print(f'Finished counting to {count_to} in {end - start} ' ) return counter if __name__ == "__main__" : start_time = time.time() to_one_hundred_million = Process(target=count, args=(100000000 ,)) to_two_hundred_million = Process(target=count, args=(200000000 ,)) to_one_hundred_million.start() to_two_hundred_million.start() to_one_hundred_million.join() to_two_hundred_million.join() end_time = time.time() print(f'Completed in {end_time - start_time} ' ) """ Finished counting to 100000000 in 4.116375923156738 Finished counting to 200000000 in 8.063395977020264 Completed in 8.145723104476929 """
进程池 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 from multiprocessing import Pooldef say_hello (name: str) -> str: return f'Hi there, {name} ' if __name__ == "__main__" : with Pool() as process_pool: hi_jeff = process_pool.apply(say_hello, args=('Jeff' ,)) hi_john = process_pool.apply(say_hello, args=('John' ,)) print(hi_jeff) print(hi_john) """ Hi there, Jeff Hi there, John """
我们使用with Pool() as process_pool创建了一个进程池。这是一个上下文管理器,因为一旦我们使用完池,我们需要适当地关闭创建的 Python 进程。
当我们实例化此池时,它将自动创建与您正在运行的计算机上的CPU内核数量相等的Python进程。您可以通过运行multiprocessing.cpu_count() 函数在Python中确定您拥有的CPU内核数
异步运行 apply 方法会阻塞,直到函数完成。这意味着,如果每次调用 say_hello 需要 10 秒钟,我们整个程序的运行时间将会约为 20 秒。
每次调用 apply 方法都会阻塞,直到我们的函数完成。如果我们想建立一个真正的并行工作流程,这是不可行的。为了解决这个问题,我们可以使用 apply_async 方法。这种方法会立即返回 AsyncResult,然后在后台开始运行进程。一旦我们有了 AsyncResult,我们就可以使用它的 get 方法来阻塞并获取函数调用的结果。
1 2 3 4 5 6 7 8 9 10 11 12 13 from multiprocessing import Pooldef say_hello (name: str) -> str: return f'Hi there, {name} ' if __name__ == "__main__" : with Pool() as process_pool: hi_jeff = process_pool.apply_async(say_hello, args=('Jeff' ,)) hi_john = process_pool.apply_async(say_hello, args=('John' ,)) print(hi_jeff.get()) print(hi_john.get())
当我们调用 apply_async 时,say_hello 的两个调用会立即在不同的进程中启动。然后,当我们调用 get 方法时,父进程将会阻塞,直到每个进程返回一个值。这使得方法可以并发运行。
进程池执行器 上面多进程程序中,如果 hi_jeff 运行了 10 秒,而 hi_john 只需 1 秒,该怎么办呢?因为 hi_jeff 先调用了 get,所以会阻塞一直等到完成后才会运行 hi_john。
还有一种需求是,如果我们需要轻松地更改并发处理方式,无缝地在进程和线程之间切换,该怎么办?
concurrent.futures 模块通过 Executor 抽象类为我们提供了这种抽象化。这个类定义了两种异步运行工作的方法。第一个是submit,它将接受一个可调用对象并返回一个Future(请注意,这不是 asyncio futures,而是concurrent.futures 模块的一部分)这相当于我们在上一节中看到的 Pool.apply_async 方法。第二个方法是map。此方法将接受可调用对象和函数参数列表,然后异步执行列表中的每个参数。它返回结果的迭代器,类似于asyncio.as_completed,即结果在完成后可用。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 import timefrom concurrent.futures import ProcessPoolExecutordef count (count_to: int) -> int: start = time.time() counter = 0 while counter < count_to: counter = counter + 1 end = time.time() print(f'Finished counting to {count_to} in {end - start} ' ) return counter if __name__ == "__main__" : with ProcessPoolExecutor() as process_pool: numbers = [1 , 3 , 100000000 , 5 , 22 ] for result in process_pool.map(count, numbers): print(result) """ Finished counting to 1 in 0.0 Finished counting to 3 in 9.5367431640625e-07 1 3 Finished counting to 5 in 1.1920928955078125e-06 Finished counting to 22 in 1.9073486328125e-06 Finished counting to 100000000 in 4.075898885726929 // 被阻塞 100000000 5 22 """
虽然看起来这与 asyncio.as_completed 的工作方式相同,但迭代的顺序是基于我们传递给数字列表的顺序确定的。这意味着,如果100000000是我们的第一个数字,我们就会被卡住等待该调用完成,然后才能打印出早先完成的其他结果。这意味着不像 asyncio.as_completed那样反应灵敏。
PoolExecutor 也可以使用 submit 的方式提交获得一个 future,然后使用 as_as_completed 的方式获取结果。并且这样的方式当前面的任务太耗时时,后面的任务并不会被阻塞。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 import timefrom concurrent.futures import ProcessPoolExecutor, as_completeddef count (count_to: int) -> int: start = time.time() counter = 0 while counter < count_to: counter = counter + 1 end = time.time() print(f'Finished counting to {count_to} in {end - start} ' ) return counter if __name__ == "__main__" : with ProcessPoolExecutor() as process_pool: todo_map = {} todo_list = [] numbers = [1 , 3 , 100000000 , 5 , 22 ] for x in numbers: future = process_pool.submit(count, x) todo_list.append(future) result = as_completed(todo_list) for x in result: print(x.result()) """ Finished counting to 1 in 1.1920928955078125e-06 Finished counting to 3 in 1.1920928955078125e-06 1 3 Finished counting to 5 in 0.0 Finished counting to 22 in 1.9073486328125e-06 // 没有被阻塞 5 22 Finished counting to 100000000 in 4.001918077468872 100000000 """
异步事件循环结合执行器 ⚠️这种方法适用于进程池和线程池
我们可以使用 run_in_executor 方法,这个方法将接受一个可调用对象和一个执行器(可以是线程池或进程池),并将在池内运行这个可调用对象。它然后返回一个可等待对象,我们可以在await语句中使用它,或将其传递给API函数,如gather。
run_in_executor 函数只接受一个可调用函数,不接受参数,所以我们可能会用到偏函数 functools.partial。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 import asyncioimport timefrom asyncio import AbstractEventLoopfrom concurrent.futures import ProcessPoolExecutorfrom functools import partialfrom typing import Listdef count (count_to: int) -> int: start = time.time() counter = 0 while counter < count_to: counter = counter + 1 end = time.time() print(f'Finished counting to {count_to} in {end - start} ' ) return counter async def main () : with ProcessPoolExecutor() as process_pool: loop: AbstractEventLoop = asyncio.get_running_loop() nums = [1 , 3 , 5 , 22 , 100000000 ] calls: List[partial[int]] = [partial(count, num) for num in nums] call_coros = [] for call in calls: call_coros.append(loop.run_in_executor(process_pool, call)) results = await asyncio.gather(*call_coros) for result in results: print(result) if __name__ == "__main__" : asyncio.run(main())
上述代码我们也可以使用 asyncio.as_completed 从子进程中获取结果:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import asyncioimport timefrom asyncio import AbstractEventLoopfrom concurrent.futures import ProcessPoolExecutorfrom functools import partialfrom typing import Listdef count (count_to: int) -> int: start = time.time() counter = 0 while counter < count_to: counter = counter + 1 end = time.time() print(f'Finished counting to {count_to} in {end - start} ' ) return counter async def main () : with ProcessPoolExecutor() as process_pool: loop: AbstractEventLoop = asyncio.get_running_loop() nums = [1 , 3 , 5 , 22 , 100000000 ] calls: List[partial[int]] = [partial(count, num) for num in nums] call_coros = [] for call in calls: call_coros.append(loop.run_in_executor(process_pool, call)) for result in asyncio.as_completed(call_coros): print(result) if __name__ == "__main__" : asyncio.run(main())
多进程锁 加锁,我们可以调用get_lock().acquire()方法, 释放锁,我们调用get_lock().release()方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 from multiprocessing import Process, Valuedef increment_value (shared_int: Value) : shared_int.get_lock().acquire() shared_int.value = shared_int.value + 1 shared_int.get_lock().release() if __name__ == '__main__' : for _ in range(100 ): integer = Value('i' , 0 ) procs = [ Process(target=increment_value, args=(integer,)), Process(target=increment_value, args=(integer,)) ] [p.start() for p in procs] [p.join() for p in procs] print(integer.value) assert (integer.value == 2 )
我们也可以使用 with 上下文管理器:
1 2 3 def increment_value (shared_int: Value) : with shared_int.get_lock(): shared_int.value = shared_int.value + 1
共享数据在定义上是在工作进程之间共享的。因此,如果我们像以前一样尝试将共享数据作为函数的参数传递,则会出现“无法对Value对象进行封装”的错误。
为了处理这个问题,我们需要把我们的共享计数器放在全局变量中,并且以某种方式让我们的工作进程知道它。我们可以使用进程池 initializer 来实现这一点。
初始化进程池来实现共享数据
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 import asynciofrom concurrent.futures import ProcessPoolExecutorfrom multiprocessing import Valueshared_counter: Value def init (counter: Value) : global shared_counter shared_counter = counter def increment () : with shared_counter.get_lock(): shared_counter.value += 1 async def main () : counter = Value('d' , 0 ) with ProcessPoolExecutor(initializer=init, initargs=(counter,)) as pool: await asyncio.get_running_loop().run_in_executor(pool, increment) print(counter.value) if __name__ == "__main__" : asyncio.run(main())
上述代码会让进程池针对每个进程,都使用参数 counter 来执行函数 init 函数。
运行既包含CPU密集和IO密集的任务
使用多进程,每个进程都有自己的线程和Python解释器。虽然多进程主要用于 CPU 密集型任务,但对于 I/O 密集型工作负载也可以有益。
上面代码中,我们现在知道如何在异步编程中使用多进程来提高 CPU 密集型任务的性能。如果我们有一项既包含CPU 密集型工作又包含 I/O 密集型操作的工作负载会怎样呢?
答案是为每个进程创建一个事件循环来使用多进程来扩展 asyncio 的功能。这有潜力改善既有 CPU 密集型又有 I/O 密集型工作负载的性能。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 68 69 70 71 72 import asyncioimport asyncpgfrom util import async_timedfrom typing import List, Dictfrom concurrent.futures.process import ProcessPoolExecutorproduct_query = \ """ SELECT * FROM product as p JOIN sku as s on s.product_id = p.product_id JOIN product_color as pc on pc.product_color_id = s.product_color_id JOIN product_size as ps on ps.product_size_id = s.product_size_id WHERE p.product_id = 100 """ async def query_product (pool) : async with pool.acquire() as connection: return await connection.fetchrow(product_query) @async_timed() async def query_products_concurrently (pool, queries) : """ 并发查询 :param pool: 连接池 :param queries: 并发次数 :return: """ queries = [query_product(pool) for _ in range(queries)] return await asyncio.gather(*queries) def run_in_new_loop (num_queries: int) -> List[Dict]: """ 新的事件循环 :param num_queries: :return: """ async def run_queries () : async with asyncpg.create_pool( host='127.0.0.1' , port=5432 , user='postgres' , password='password' , database='products' , min_size=6 , max_size=6 ) as pool: return await query_products_concurrently(pool, num_queries) results = [dict(result) for result in asyncio.run(run_queries())] return results @async_timed() async def main () : loop = asyncio.get_running_loop() pool = ProcessPoolExecutor() tasks = [loop.run_in_executor(pool, run_in_new_loop, 10000 ) for _ in range(5 )] all_results = await asyncio.gather(*tasks) total_queries = sum([len(result) for result in all_results]) print(f'Retrieved {total_queries} products the product database.' ) if __name__ == "__main__" : asyncio.run(main())
上述代码,将同时启动50,000个查询,每个进程10,000个查询。这大大的提高了查询的效率。
第七章
内部默认线程数的公式为 min(32,os.cpu_count()+ 4)。这将导致工作线程的最大(上限)边界为 32,最小(下限)边界为 5。这是默认分配的,如果不手工指定的话。
使用线程池执行 Request 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import timeimport requestsfrom concurrent.futures import ThreadPoolExecutordef get_status_code (url: str) -> int: response = requests.get(url) return response.status_code start = time.time() with ThreadPoolExecutor() as pool: urls = ['https://www.baidu.com' for _ in range(1000 )] results = pool.map(get_status_code, urls) for result in results: pass end = time.time() print(f'finished requests in {end - start:.4 f} second(s)' ) """ finished requests in 68.5113 second(s) """
上述代码中,哪怕使用 with ThreadPoolExecutor(max_workers=1000) as pool 来增加线程的数量,效果还是不能和协程相对比,因为线程的创建需要一定的开销。
使用线程池执行器与asyncio 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 import functoolsimport requestsimport asynciofrom concurrent.futures import ThreadPoolExecutorfrom util import async_timeddef get_status_code (url: str) -> int: response = requests.get(url) return response.status_code @async_timed() async def main () : loop = asyncio.get_running_loop() with ThreadPoolExecutor() as pool: urls = ['https://www.baidu.com' for _ in range(1000 )] tasks = [loop.run_in_executor(pool, functools.partial(get_status_code, url)) for url in urls] results = await asyncio.gather(*tasks) print(results) asyncio.run(main())
与不使用 asyncio 的线程池相比,此方法不会产生任何性能优势,但是在等待 await asyncio.gather 完成时,其他代码有机会可以运行。
默认执行器 run_in_executor 方法的 executor 参数可以为 None。在这种情况下,run_in_executor 将使用事件循环的默认执行程序。除非我们使用 loop.set_default_executor 方法设置自定义执行程序,否则默认执行程序将始终默认为ThreadPoolExecutor。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 import asyncioimport functoolsimport requestsfrom util import async_timeddef get_status_code (url: str) -> int: response = requests.get(url) return response.status_code @async_timed() async def main () : loop = asyncio.get_running_loop() urls = ['https://www.baidu.com' for _ in range(1000 )] tasks = [loop.run_in_executor(None , functools.partial(get_status_code, url)) for url in urls] results = await asyncio.gather(*tasks) print(results) asyncio.run(main())
上述代码还可以更近一步的简写,使用 to_thread 协程可以消除使用 functools.partial 和 asyncio.get_running_loop 的调用,从而减少我们的总代码行数。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import requestsimport asynciofrom util import async_timeddef get_status_code (url: str) -> int: response = requests.get(url) return response.status_code @async_timed() async def main () : urls = ['https://www.baidu.com' for _ in range(1000 )] tasks = [asyncio.to_thread(get_status_code, url) for url in urls] results = await asyncio.gather(*tasks) print(results) asyncio.run(main())
线程锁 在使用多进程时,创建的进程默认不共享内存。这意味着我们需要创建特殊的共享内存对象,并正确初始化它们,以便每个进程都可以从该对象读取并向其写入。由于线程可以访问其父进程的相同内存,因此我们不再需要这样做,线程可以直接访问共享变量。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 import functoolsimport requestsimport asynciofrom concurrent.futures import ThreadPoolExecutorfrom threading import Lockfrom util import async_timedcounter_lock = Lock() counter: int = 0 def get_status_code (url: str) -> int: global counter response = requests.get(url) with counter_lock: counter = counter + 1 return response.status_code async def reporter (request_count: int) : while counter < request_count: print(f'Finished {counter} /{request_count} requests' ) await asyncio.sleep(.5 ) @async_timed() async def main () : loop = asyncio.get_running_loop() with ThreadPoolExecutor() as pool: request_count = 50 urls = ['https://www.baidu.com' for _ in range(request_count)] reporter_task = asyncio.create_task(reporter(request_count)) tasks = [loop.run_in_executor(pool, functools.partial(get_status_code, url)) for url in urls] results = await asyncio.gather(*tasks) await reporter_task print(results) asyncio.run(main()) """ 开始执行函数 main 参数: () {} Finished 0/50 requests Finished 0/50 requests Finished 16/50 requests Finished 32/50 requests Finished 49/50 requests [200, 200, 200, 200, 200, ... , 200] """
可重入线程锁 可重入锁是一种特殊的锁,它可以被同一线程多次获取,允许该线程“重新进入”临界区。线程模块提供了RLock类中的可重入锁。可重入锁通过保持递归计数来工作。每当我们从首次获取锁的线程那里获取锁时,计数增加,每当我们释放锁时,计数减少。当计数为0时,锁最终释放以供其他线程获取。
1 2 3 from threading import Rlock list_lock = RLock()
其他函数 call_soon_threadsafe。该函数接受一个 Python 函数(而不是协程)并在下一次 asyncio 事件循环的迭代中以线程安全的方式将其安排为可执行。第二个函数是 asyncio.run_coroutine_threadsafe。该函数接受一个协程并以线程安全的方式提交它,立即返回一个 future,我们可以使用它来访问协程的结果。重要的是,并令人困惑的是,这个未来不是 asyncio 未来,而是来自 concurrent.futures模块。背后的逻辑是,asyncio future不是线程安全的,但是 concurrent.futures future 是线程安全的。但是,这个未来类具有与 asyncio 模块的未来相同的功能。
第九章 ASGI 有一些实现可供选择,但我们将使用一种流行的实现,称为 Uvicorn 。Uvicorn 建立在 uvloop 和 httptools 之上,它们是 asyncio 事件循环的快速 C 实现。
但最好的做法是与Gunicorn一起使用Uvicorn ,因为Gunicorn会有逻辑,在崩溃时重启工作程序。
Starlette是由Encode创建的小型ASGI兼容框架,也是Uvicorn和Django REST framework等其他流行库的创造者。它提供相当不错的性能。
使用 Gunicorn 部署 ASGI 应用 使用 Gunicorn 部署 ASGI 应用会发生什么?当我们使用 Gunicorn 部署 ASGI 应用时,应用能正常运行,但每次都会创建一个新的事件循环。
第十一章 asyncio 锁 在使用 await 的时候,会等待执行,这时如果有其他协程将数据修改了,那么会发生意想不到的情况。
asyncio锁的操作类似于 multiprocessing 和 multithreading模块中的锁。我们获取一个锁,在关键部分内执行工作,执行完后释放锁,让其他 task 获取它。主要的区别在于,asyncio 锁是可等待的对象,在被阻塞时挂起协程执行。这意味着当一个协程被阻塞等待获取锁时,其他代码可以运行。此外,asyncio锁也是异步上下文管理器,推荐使用async with语法来使用它们。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 import asynciofrom asyncio import Lockfrom util import delayasync def a (lock: Lock) : print('等待 a 获取锁' ) async with lock: print('a 获取到了锁' ) await delay(2 ) print('a 释放了锁' ) async def b (lock: Lock) : print('等待 b 获取锁' ) async with lock: print('b 获取到了锁' ) await delay(2 ) print('b 释放了锁' ) async def main () : lock = Lock() await asyncio.gather(a(lock), b(lock)) asyncio.run(main()) """ 等待 a 获取锁 a 获取到了锁 sleeping for 2 second(s) 等待 b 获取锁 finished sleeping for 2 second(s) a 释放了锁 b 获取到了锁 sleeping for 2 second(s) finished sleeping for 2 second(s) b 释放了锁 """
由于 asyncio 的单线程特性,您很可能不经常需要在 asyncio 代码中使用锁,因为它可以避免许多并发问题。即使出现竞争条件,有时您也可以重构代码,使状态在协程被挂起时不被修改(例如使用不可变对象)。当您无法以这种方式进行重构时,这时候就考虑使用 asyncio 锁。
信号量 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 import asynciofrom asyncio import Semaphoreasync def operation (semaphore: Semaphore) : print('等待获取信号量...' ) async with semaphore: print('获取到信号量!' ) await asyncio.sleep(2 ) print('释放信号量!' ) async def main () : semaphore = Semaphore(2 ) await asyncio.gather(*[operation(semaphore) for _ in range(4 )]) asyncio.run(main()) """ 等待获取信号量... 获取到信号量! 等待获取信号量... 获取到信号量! 等待获取信号量... 等待获取信号量... 释放信号量! 释放信号量! 获取到信号量! 获取到信号量! 释放信号量! 释放信号量! """
在我们的主协程中,我们创建了一个信号量,并将其数量限制为2,表示我们可以在阻塞之前进行两次获取,获取之后直到释放之前,其余的两个协程都处于等待获取状态。
例如我们可以使用信号量,来限制 API 请求:
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 import asynciofrom asyncio import Semaphorefrom aiohttp import ClientSessionasync def get_url (url: str, session: ClientSession, semaphore: Semaphore) : print('等待获取信号量...' ) async with semaphore: print('获取到信号量,请求中...' ) response = await session.get(url) print('请求完成' ) return response.status async def main () : semaphore = Semaphore(10 ) async with ClientSession() as session: tasks = [get_url('https://www.baidu.com' , session, semaphore) for _ in range(1000 )] await asyncio.gather(*tasks) asyncio.run(main())
有界信号量
asyncio 提供了 BoundedSemaphore。该信号量的行为与我们一直使用的信号量完全相同,其关键区别在于,如果我们调用 release 释放超过了信号量的数量,则会抛出 ValueError: BoundedSemaphore released too many times 异常。
1 2 3 4 5 6 7 8 9 10 11 12 13 import asynciofrom asyncio import BoundedSemaphoreasync def main () : semaphore = BoundedSemaphore(1 ) await semaphore.acquire() semaphore.release() semaphore.release() asyncio.run(main())
Event Event类会跟踪一个标志,指示事件是否已经发生。我们可以使用set和clear两种方法来控制此标志。set方法将此内部标志设置为True,并通知任何正在等待的人事件已经发生。clear方法将此内部标志设置为False,并导致任何等待事件的人现在被阻止。
Event 类有一个协程方法叫做 wait。当我们await这个协程时,它会阻塞直到有人在事件对象上调用 set。一旦发生这种情况,任何调用 wait 的额外调用都不会阻塞,并且会立即返回。如果我们在调用 set 后调用 clear,那么再次调用 wait 将开始阻塞,直到再次调用 set。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 import asyncioimport functoolsfrom asyncio import Eventdef trigger_event (event: Event) : event.set() async def do_work_on_event (event: Event) : print('等待 event...' ) await event.wait() print('开始工作!' ) await asyncio.sleep(1 ) print('完成工作!' ) event.clear() async def main () : event = asyncio.Event() asyncio.get_running_loop().call_later(5.0 , functools.partial(trigger_event, event)) await asyncio.gather(do_work_on_event(event), do_work_on_event(event)) asyncio.run(main()) """ 等待 event... 等待 event... 开始工作! 开始工作! 完成工作! 完成工作! """
上述代码中 await event.wait() 将等待 event.set() 的执行,一旦执行后,所有阻塞在这里的协程都会继续执行。
Conditions 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 import asynciofrom asyncio import Conditionasync def do_work (condition: Condition, name: str) : while True : async with condition: print(f'{name} 等待 notify_all ...' ) await condition.wait() print(f'{name} 监听到 notify_all 事件...' ) await asyncio.sleep(1 ) print(f'{name} 工作结束,释放锁.' ) async def fire_event (condition: Condition) : while True : await asyncio.sleep(5 ) async with condition: print('fire_event,即将通知所有开始工作.' ) condition.notify_all() print('fire_event 通知工作结束.' ) async def main () : condition = Condition() asyncio.create_task(fire_event(condition)) await asyncio.gather(do_work(condition, "work1" ), do_work(condition, "work2" )) asyncio.run(main()) """ work1 等待 notify_all ... work2 等待 notify_all ... fire_event,即将通知所有开始工作. fire_event 通知工作结束. work1 监听到 notify_all 事件... work1 工作结束,释放锁. work2 监听到 notify_all 事件... work2 工作结束,释放锁. work1 等待 notify_all ... work2 等待 notify_all ... fire_event,即将通知所有开始工作. fire_event 通知工作结束. work1 监听到 notify_all 事件... work1 工作结束,释放锁. work2 监听到 notify_all 事件... work2 工作结束,释放锁. ...... """
上述代码中,我们创建了两个协程方法:do_work 和 fire_event。do_work 方法获取 condition,类似于获取锁,并调用 condition 的 wait 协程方法。wait 协程方法将一直阻塞,直到有人调用该条件的 notify_all方法。
fire_event 协程方法会睡眠 5s,然后获取 condition 并调用 notify_all 方法,唤醒当前正在等待 condition 的任何任务。
主协程中,创建一个 fire_event 任务和两个 do_work 任务并同时运行。
第十二章 队列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 import asynciofrom asyncio import Queuefrom random import randrangefrom typing import Listclass Product : def __init__ (self, name: str, checkout_time: float) : self.name = name self.checkout_time = checkout_time class Customer : def __init__ (self, customer_id: int, products: List[Product]) : self.customer_id = customer_id self.products = products async def checkout_customer (queue: Queue, cashier_number: int) : while not queue.empty(): customer: Customer = queue.get_nowait() print(f'收营员 {cashier_number} ' f'结账客户 ' f'{customer.customer_id} ' ) for product in customer.products: print(f"收营员 {cashier_number} " f"正在给" f"{customer.customer_id} 's 结算 {product.name} " ) await asyncio.sleep(product.checkout_time) print(f'收营员 {cashier_number} ' f'完成对' f'{customer.customer_id} 的结算' ) queue.task_done() async def main () : customer_queue = Queue() all_products = [ Product('beer' , 2 ), Product('bananas' , .5 ), Product('sausage' , .2 ), Product('diapers' , .2 ) ] for i in range(10 ): products = [all_products[randrange(len(all_products))] for _ in range(randrange(10 ))] customer_queue.put_nowait(Customer(i, products)) cashiers = [asyncio.create_task(checkout_customer(customer_queue, i)) for i in range(3 )] await asyncio.gather(customer_queue.join(), *cashiers) asyncio.run(main())
从队列中获取和设置元素有两种方式,阻塞[put(), get()]和非阻塞[get_nowait(), put_nowait()]。
上述代码中,队列不为空,所以使用 get_nowait 方法不会发生异常,但是顾客并不是一直存在的。所以当队列中顾客为空时,使用 get_nowait 就会发生错误。解决这个问题的方法就是使用阻塞的 put 和 get 方法。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 45 46 47 48 49 50 51 52 53 54 55 56 57 58 59 60 61 62 63 64 65 66 67 import asynciofrom asyncio import Queuefrom random import randrangeclass Product : def __init__ (self, name: str, checkout_time: float) : self.name = name self.checkout_time = checkout_time class Customer : def __init__ (self, customer_id, products) : self.customer_id = customer_id self.products = products async def checkout_customer (queue: Queue, cashier_number: int) : while True : customer: Customer = await queue.get() print(f'收营员 {cashier_number} ' f'结账客户 ' f'{customer.customer_id} ' ) for product in customer.products: print(f"收营员 {cashier_number} " f"正在给" f"{customer.customer_id} 's 结算 {product.name} " ) await asyncio.sleep(product.checkout_time) print(f'收营员 {cashier_number} ' f'完成对' f'{customer.customer_id} 的结算' ) queue.task_done() def generate_customer (customer_id: int) -> Customer: all_products = [ Product('beer' , 2 ), Product('bananas' , .5 ), Product('sausage' , .2 ), Product('diapers' , .2 ) ] products = [all_products[randrange(len(all_products))] for _ in range(randrange(10 ))] return Customer(customer_id, products) async def customer_generator (queue: Queue) : customer_count = 0 while True : customers = [generate_customer(i) for i in range(customer_count, customer_count + randrange(5 ))] for customer in customers: print('客户正在等待排队...' ) await queue.put(customer) print('客户已加入排队!' ) customer_count = customer_count + len(customers) await asyncio.sleep(1 ) async def main () : customer_queue = Queue(5 ) customer_producer = asyncio.create_task(customer_generator(customer_queue)) cashiers = [asyncio.create_task(checkout_customer(customer_queue, i)) for i in range(3 )] await asyncio.gather(customer_producer, *cashiers) asyncio.run(main())
优先级队列 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 import asynciofrom asyncio import Queue, PriorityQueuefrom typing import Tupleasync def worker (queue: Queue) : while not queue.empty(): work_item: Tuple[int, str] = await queue.get() print(f'Processing work item {work_item} ' ) queue.task_done() async def main () : priority_queue = PriorityQueue() work_items = [ (3 , 'Lowest priority' ), (2 , 'Medium priority' ), (1 , 'High priority' ) ] worker_task = asyncio.create_task(worker(priority_queue)) for work in work_items: priority_queue.put_nowait(work) await asyncio.gather(priority_queue.join(), worker_task) asyncio.run(main()) """ Processing work item (1, 'High priority') Processing work item (2, 'Medium priority') Processing work item (3, 'Lowest priority') """
上述代码中,work_items 第一个元素是表示优先级的整数,第二个元素是任何任务数据。默认队列实现查看元组的第一个值以确定优先级,最小的数字优先级最高。
自定义数据类使用优先级队列
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 import asynciofrom asyncio import Queue, PriorityQueuefrom dataclasses import dataclass, field@dataclass(order=True) class WorkItem : priority: int data: str = field(compare=False ) async def worker (queue: Queue) : while not queue.empty(): work_item: WorkItem = await queue.get() print(f'Processing work item {work_item} ' ) queue.task_done() async def main () : priority_queue = PriorityQueue() work_items = [ WorkItem(3 , 'Lowest priority' ), WorkItem(2 , 'Medium priority' ), WorkItem(1 , 'High priority' ) ] worker_task = asyncio.create_task(worker(priority_queue)) for work in work_items: priority_queue.put_nowait(work) await asyncio.gather(priority_queue.join(), worker_task) asyncio.run(main()) """ Processing work item WorkItem(priority=1, data='High priority') Processing work item WorkItem(priority=2, data='Medium priority') Processing work item WorkItem(priority=3, data='Lowest priority') """
栈 LIFO 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 import asynciofrom asyncio import Queue, LifoQueuefrom dataclasses import dataclass, field@dataclass(order=True) class WorkItem : priority: int order: int data: str = field(compare=False ) async def worker (queue: Queue) : while not queue.empty(): work_item: WorkItem = await queue.get() print(f'出栈: {work_item} ' ) queue.task_done() async def main () : lifo_queue = LifoQueue() work_items = [ WorkItem(3 , 1 , 'Lowest priority first' ), WorkItem(3 , 2 , 'Lowest priority second' ), WorkItem(3 , 3 , 'Lowest priority third' ), WorkItem(2 , 4 , 'Medium priority' ), WorkItem(1 , 5 , 'High priority' ) ] worker_task = asyncio.create_task(worker(lifo_queue)) for work in work_items: print(f"入栈: {work} " ) lifo_queue.put_nowait(work) await asyncio.gather(lifo_queue.join(), worker_task) asyncio.run(main())
第十四章 检测是否为协程 asyncio 提供了几个方便函数来帮助我们实现这一点:asyncio.iscoroutine和asyncio.iscoroutinefunction。这些函数可以让我们测试可调用对象是否为协程,从而让我们根据此应用不同的逻辑。
强制运行事件循环 通过将零传递给 asyncio.sleep 来暂停当前的协程并强制迭代事件循环。
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 29 30 31 32 33 34 35 36 37 38 39 40 41 42 43 44 import asynciofrom util import delayasync def create_tasks_no_sleep () : task1 = asyncio.create_task(delay(1 )) task2 = asyncio.create_task(delay(2 )) print("获取到任务:" ) await asyncio.gather(task1, task2) async def create_tasks_sleep () : task1 = asyncio.create_task(delay(1 )) await asyncio.sleep(0 ) task2 = asyncio.create_task(delay(2 )) await asyncio.sleep(0 ) print("获取到任务:" ) await asyncio.gather(task1, task2) async def main () : print('--- 没有使用 asyncio.sleep(0) ---' ) await create_tasks_no_sleep() print('--- 使用 asyncio.sleep(0) ---' ) await create_tasks_sleep() asyncio.run(main()) """ --- 没有使用 asyncio.sleep(0) --- 获取到任务: sleeping for 1 second(s) sleeping for 2 second(s) finished sleeping for 1 second(s) finished sleeping for 2 second(s) --- 使用 asyncio.sleep(0) --- sleeping for 1 second(s) sleeping for 2 second(s) 获取到任务: finished sleeping for 1 second(s) finished sleeping for 2 second(s) """
使用 sleep(0) 会强制进行事件循环的迭代,从而导致我们的任务中的代码立即执行。
asyncio.sleep(0) 强制执行事件循环吗?
ChatGPT: asyncio.sleep(0)用于提醒事件循环 “我暂时不需要运行,请检查是否有其他任务需要执行”,而不是强制执行事件循环。强制执行事件循环的方式通常是使用asyncio.get_event_loop().run_until_complete(...)或asyncio.get_event_loop().run_forever()等方法,但这样的用法应该谨慎,以避免阻塞事件循环的正常执行。
使用uvloop作为事件循环 1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 import asynciofrom asyncio import StreamReader, StreamWriterimport uvloopasync def connected (reader: StreamReader, writer: StreamWriter) : line = await reader.readline() writer.write(line) await writer.drain() writer.close() await writer.wait_closed() async def main () : server = await asyncio.start_server(connected, port=9000 ) await server.serve_forever() uvloop.install() asyncio.run(main()) """ loop = uvloop.new_event_loop() asyncio.set_event_loop(loop) """
重要的部分是在调用 asyncio.run(main()) 之前调用它。在实现上,asyncio.run 会调用 get_event_loop 来创建一个事件循环(如果不存在的话)。所以如果要达到替换的效果,那么需要在 asyncio.run(main()) 之前调用它。